Dynamic Programming
Contents: Bellman equation, contraction mapping, Value Function Iteration (VFI), Policy Iteration, Endogenous Grid Method (EGM), numerical examples (VFI code) and exercises.
This notebook contains lecture notes (markdown) and runnable Python examples for the numerical sections.
Learning objectives¶
After working through this notebook, you should be able to:
State and interpret the Bellman equation and the principle of optimality.
Sketch why the Bellman operator is a contraction and why a unique fixed point exists.
Implement Value Function Iteration (VFI) for a simple stochastic consumption–savings problem.
Know advantages and limitations of alternative solution methods: policy iteration, EGM, collocation.
Connect Bellman/Euler approaches and understand numerical tradeoffs.
What is the Bellman equation?¶
The Bellman equation is the fundamental recursive identity in dynamic programming and Markov decision processes (MDPs). It encodes the principle of optimality: the value of being in a state equals the best immediate reward plus the (discounted) value of the next state when following an optimal policy.
Deterministic Bellman equation¶
State , action . Deterministic law . Discount factor .
The Bellman equation:
Example (deterministic consumption–savings):
State: assets . Control: next-period assets (or consumption ). Budget: .
Bellman:
Using the envelope theorem and FOC you can derive the Euler equation when interior.
General (discrete-time, stochastic) form¶
Let:
be the current state (from state space ),
an action (from the action set ),
the immediate reward when taking in ,
the probability of next state ,
the discount factor, and
the value function (maximal expected discounted reward starting from ).
The Bellman optimality equation is
For a fixed policy the Bellman (policy) equation is
🍰 The Cake-Eating Problem¶
Classic problem in programming: you are given a whole cake of some size .
How should you choose a consumption stream?
Maximize lifetime utility
Account for discounting
The cake will go bad at some point
Dynamic problems involve returns now vs. returns later.
An obvious tradeoff:
Delaying consumption is costly (discount factor)
But delaying may be beneficial (due to concave utility)
eat some today and some tomorrow
How much to eat today? (assume it goes bad in days)
all of it on day 1?
each day?
But you’d rather eat more today than tomorrow.
Implication: eat more on the first day, less and less on the following days.
Analytical Solution of the Cake-Eating Problem¶
We start with a finite horizon , an initial cake size , and no uncertainty. The agent chooses a consumption sequence .
1. Setup¶
Initial cake: given.
Law of motion for the cake:
No borrowing and no negative cake:
Cake spoils after date , so it is optimal to end with no cake:
Preferences: CRRA utility
and discount factor .
The agent maximizes:
subject to the cake dynamics and given.
2. Intertemporal budget constraint¶
From
we can iterate forward:
...
.
Imposing gives:
So the resource constraint is simply: total consumption over the periods equals the initial cake.
3. Euler equation¶
We can write the Lagrangian (or rely on dynamic programming, same Euler):
Maximize
subject to .
Introduce a multiplier on the resource constraint:
First-order condition for each :
For CRRA,
So
Take two adjacent periods, and :
Set them equal (since both equal ):
Divide both sides by :
Rearrange:
Raise both sides to the power :
This is the Euler equation in this problem: consumption follows a geometric path.
Define
Then
So consumption is geometrically declining over time.
4. Use the resource constraint to pin down ¶
We have:
and the resource constraint:
Substitute the geometric sequence:
Solve for :
Recall , so
Then the entire path is:
This is the analytic solution for the optimal consumption path.
5. Log-utility as a special case¶
For log utility, , this corresponds to the limit .
The Euler equation becomes:
So now and
The resource constraint:
Hence
And the path:
6. Infinite-horizon case (for completeness)¶
If we let , the cake never “spoils,” but the horizon is infinite and discounting ensures finite utility.
For , the infinite geometric sum is:
The resource constraint becomes:
So
Substitute :
For log utility (), this becomes:
7. Summary of the analytical solution¶
Euler equation (CRRA):
Finite-horizon optimal consumption path:
Log-utility special case ():
Infinite horizon (no spoilage, but discounting):
and, for log utility,
This is the full analytic solution of the cake-eating problem: the optimal consumption path is geometric, determined by the discount factor , the curvature , the horizon , and the initial cake size .
💡 A simple example¶
Preferences:
specifically, CRRA preferences:
where is the amount of cake eaten at time .
Discount factor:
Curvature of utility:
The present value of the consumption stream is:
Goal: maximize by choosing the sequence .
Size of cake at time :
And, of course, .
Let be the maximum lifetime utility attainable when you have units of cake left:
The Bellman equation¶
The value function satisfies the Bellman equation:
Where:
is the state variable
is the control (action) variable
and are parameters
First-order conditions¶
Substitute the constraint into the objective function:
✅ Deriving the Euler Equation in the Cake-Eating Problem¶
We start with the objective for two adjacent periods after substituting the resource constraint:
Define consumptions as
So the objective can be written as
We now take the derivative with respect to .
Step 1. Derivative of the first term¶
Since , this becomes
Step 2. Derivative of the second term¶
Here , so we get
Step 3. First-order condition¶
Add the two derivatives and set equal to zero:
Simplify:
Step 4. Euler equation (general form)¶
Relabel indices (replace by ) to obtain the standard Euler equation:
💡 Interpretation¶
The Euler equation equates the marginal utility of consuming today with the discounted marginal utility of consuming tomorrow.
It describes the optimal intertemporal tradeoff between consuming now and saving for later.
With CRRA utility , it implies
so consumption declines geometrically over time.
Solution¶
Using CRRA utility:
Solve this backward in time.
In the optimum, no cake should be left over: .
So .
By recursive substitution, the initial consumption is:
And using , we can find the entire path of consumption over time.
Summary¶
The cake-eating problem illustrates intertemporal choice:
Tradeoff between consuming today vs. saving for tomorrow.
Discounting captures impatience.
Concavity captures diminishing marginal utility.
The Bellman equation formulation:
provides the foundation for dynamic programming and recursive methods in economics.
from IPython.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))import numpy as np
import matplotlib.pyplot as plt
import math as m
from scipy import stats as st
from scipy import optimize
from scipy.optimize import minimize_scalar, bisect
from typing import NamedTuple
import time # Imports system time module to time your script
plt.close('all') # close all open figures
T = 9
beta = 0.96
kv = np.zeros(T+1,float)
cv = np.zeros(T+1,float)
uv = np.zeros(T+1,float)
kv[0] = 100 # k0
cv[0] = (1.0-beta)/(1.0-beta**(T+1)) * kv[0] # c0
uv[0] = np.log(cv[0])
for i in range(1,T+1):
#print "i=" + str(i)
cv[i] = beta * cv[i-1]
kv[i] = kv[i-1] - cv[i-1]
# Period utility with discounting
uv[i] = beta**i *np.log(cv[i])
np.sum(uv) # total utility
print("cv = " + str(cv))
print("kv = " + str(kv))cv = [11.93433618 11.45696274 10.99868423 10.55873686 10.13638738 9.73093189
9.34169461 8.96802683 8.60930576 8.26493353]
kv = [100. 88.06566382 76.60870108 65.61001685 55.05127999
44.91489261 35.18396072 25.84226611 16.87423928 8.26493353]
fig, ax = plt.subplots(2,1)
plt.subplots_adjust(wspace=0.4, hspace=0.8)
#
ax[0].plot(cv, '-o')
ax[0].set_ylabel(r'$c^*_t$')
ax[0].set_xlabel('Period t')
ax[0].set_title('Optimal Consumption')
#
ax[1].plot(kv, '-o')
ax[1].set_ylabel(r'$k_t$')
ax[1].set_xlabel('Period t')
ax[1].set_title('Cake size')
#
plt.show()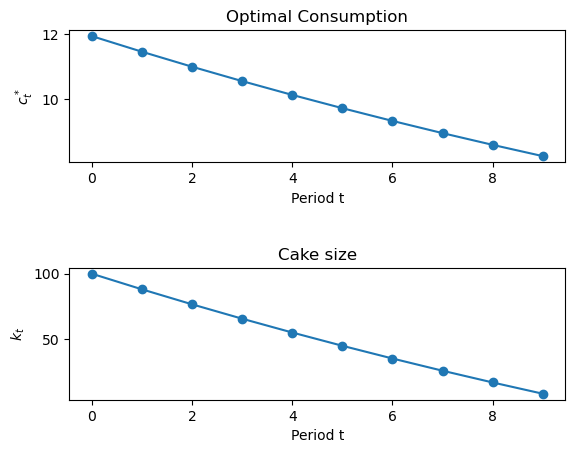
From the lecture notes and using as the utility function, the maximization problem gives the solution as
that solves the Bellman equation and therefore equals the value function. Note that this analytic solution is only possible due to the CRRA preferences. We can explore this a little deeper using Python to understand what is going on. The utility function and value function in Python:
def u(c, γ):
return c**(1 - γ) / (1 - γ)
def v_star(k, β, γ):
return (1 - β**(1 / γ))**(-γ) * u(k, γ)Let’s see this function for some parameters.
β, γ = 0.95, 1.2
k_grid = np.linspace(0.1, 5, 100)
fig, ax = plt.subplots()
ax.plot(k_grid, v_star(k_grid, β, γ), label='value function')
ax.set_xlabel('$k$', fontsize=12)
ax.legend(fontsize=12)
plt.show()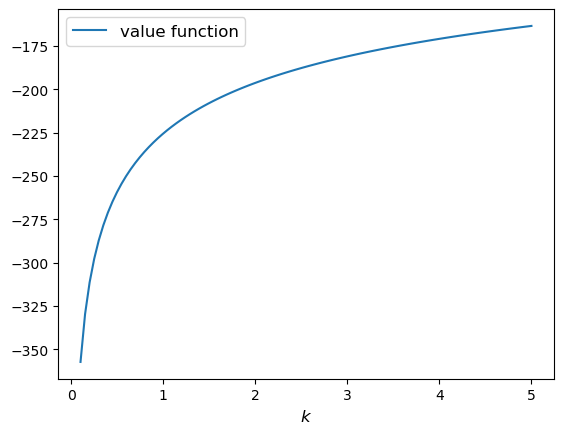
Homework. You have now seen how to solve the deterministic case. Suppose you have a sneaky sister who pops in randomly and eats some of the cake. With some probability when you go to get some cake there is less there than you remembered.
(A) Intuition...how will this affect your eating of the cake? That is, given the size of the cake you are left with, should you eat more or less compared to the no sister case?
(B) Write some python code to explore this problem. Is your intuition correct? If so, is it really correct? If not, why not?
"""
Cake-eating with a sneaky sister (stochastic shrinkage of leftover cake).
We solve the infinite-horizon DP by value function iteration (VFI) on a grid.
Timeline each period:
1) You observe current cake x
2) You choose consumption c = m*x, where m in (0,1)
3) You leave a = x - c
4) Sister may eat a fraction d of what you left:
x' = a with prob (1-p)
x' = (1-d)*a with prob p
This code makes TWO scenarios:
- Scenario A: parameters where you eat MORE with the sister than without.
- Scenario B: parameters where you eat LESS with the sister than without.
It then makes two plots (one per scenario), each showing:
- policy function c(x) with/without sister
- a simulated consumption path with/without sister
No “consume-all then zero utility” bug: we exclude x=0 and disallow m=1 (so c<x).
"""
# ---------- Utility ----------
def u_crra(c, gamma):
c = np.asarray(c)
# big negative penalty if c <= 0
out = np.full_like(c, -1e15, dtype=float)
ok = c > 0
if gamma == 1.0:
out[ok] = np.log(c[ok])
else:
out[ok] = (c[ok] ** (1.0 - gamma) - 1.0) / (1.0 - gamma)
return out
# ---------- Linear interpolation on monotone grid ----------
def interp_1d(xgrid, y, xq):
xq = np.asarray(xq)
xq = np.clip(xq, xgrid[0], xgrid[-1])
idx = np.searchsorted(xgrid, xq, side="right") - 1
idx = np.clip(idx, 0, len(xgrid) - 2)
x0, x1 = xgrid[idx], xgrid[idx + 1]
y0, y1 = y[idx], y[idx + 1]
w = (xq - x0) / (x1 - x0 + 1e-32)
return (1.0 - w) * y0 + w * y1
# ---------- VFI solver (vectorized over actions) ----------
def solve_cake(beta=0.95, gamma=2.0, p=0.25, d=0.10,
x_max=1.0, nx=800, nm=250,
eps_x=1e-6, eps_m=1e-6,
tol=1e-8, maxit=2000):
"""
Returns:
x : state grid (nx,)
V : value function (nx,)
c_pol : optimal consumption policy c(x) on the grid (nx,)
m_pol : optimal share m(x)=c/x on the grid (nx,)
"""
# Avoid x=0 to prevent "free" terminal at zero consumption
x = np.linspace(eps_x, x_max, nx)
# Actions as consumption shares m in (0,1). Avoid 0 and 1.
m_grid = np.linspace(eps_m, 1.0 - eps_m, nm) # (nm,)
V = np.zeros(nx)
# Precompute x repeated for broadcasting
X = x[None, :] # (1,nx)
M = m_grid[:, None] # (nm,1)
for it in range(maxit):
# consumption and leftover for every (m, x)
C = M * X # (nm,nx)
A = X - C # (nm,nx)
# expected continuation value
V_A = interp_1d(x, V, A) # (nm,nx)
V_shrunk = interp_1d(x, V, (1.0 - d) * A) # (nm,nx)
EV = (1.0 - p) * V_A + p * V_shrunk # (nm,nx)
# Bellman RHS
RHS = u_crra(C, gamma) + beta * EV # (nm,nx)
# maximize over m for each x
V_new = RHS.max(axis=0) # (nx,)
argm = RHS.argmax(axis=0) # (nx,)
m_pol = m_grid[argm]
c_pol = m_pol * x
diff = np.max(np.abs(V_new - V))
V = V_new
if diff < tol:
# print(f"Converged in {it+1} iterations, sup diff={diff:g}")
break
else:
raise RuntimeError(f"VFI did not converge in {maxit} iterations. Last diff={diff:g}")
return x, V, c_pol, m_pol
# ---------- Simulation ----------
def simulate_path(x_grid, m_pol_grid, x0=1.0, T=50, p=0.25, d=0.10, seed=0):
"""
Simulates one path using m(x)=c/x policy and the sister shock.
Returns:
x_path: (T+1,)
c_path: (T,)
sister: (T,) bool
"""
rng = np.random.default_rng(seed)
x_path = np.empty(T + 1)
c_path = np.empty(T)
sister = np.empty(T, dtype=bool)
x_path[0] = x0
for t in range(T):
xt = x_path[t]
# interpolate m(x) on the grid, clamp to valid range
mt = float(interp_1d(x_grid, m_pol_grid, xt))
mt = min(max(mt, 1e-9), 1.0 - 1e-9)
ct = mt * xt
at = xt - ct
hit = (rng.random() < p)
xt_next = (1.0 - d) * at if hit else at
c_path[t] = ct
sister[t] = hit
x_path[t + 1] = xt_next
return x_path, c_path, sister
# ---------- Helper: solve deterministic vs sister and plot ----------
def run_scenario(name, beta, gamma, p, d, x0=1.0, T=40, nx=800, nm=250, seed=123):
# Deterministic benchmark (no sister)
x, V0, c0, m0 = solve_cake(beta=beta, gamma=gamma, p=0.0, d=0.0, nx=nx, nm=nm)
# With sister
x, V1, c1, m1 = solve_cake(beta=beta, gamma=gamma, p=p, d=d, nx=nx, nm=nm)
# Quick numeric checks at high cake
print(f"\n=== {name} ===")
print(f"params: beta={beta}, gamma={gamma}, p={p}, d={d}")
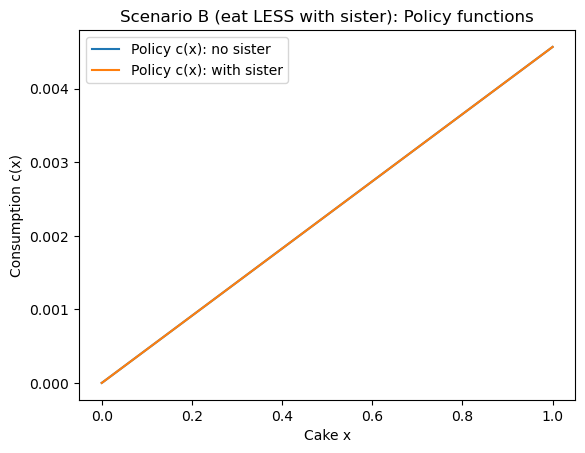
print(f"At x≈1: c_no_sister={c0[-1]:.4f}, c_sister={c1[-1]:.4f}, diff={c1[-1]-c0[-1]:+.4f}")
print(f"Mean diff over grid: {float(np.mean(c1 - c0)):+.6f}")
# Simulate consumption paths
x_path0, c_path0, _ = simulate_path(x, m0, x0=x0, T=T, p=0.0, d=0.0, seed=seed)
x_path1, c_path1, s = simulate_path(x, m1, x0=x0, T=T, p=p, d=d, seed=seed)
# Plot: policy function + simulated path
t = np.arange(T)
plt.figure()
plt.plot(x, c0, label="Policy c(x): no sister")
plt.plot(x, c1, label="Policy c(x): with sister")
plt.xlabel("Cake x")
plt.ylabel("Consumption c(x)")
plt.title(f"{name}: Policy functions")
plt.legend()
plt.show()
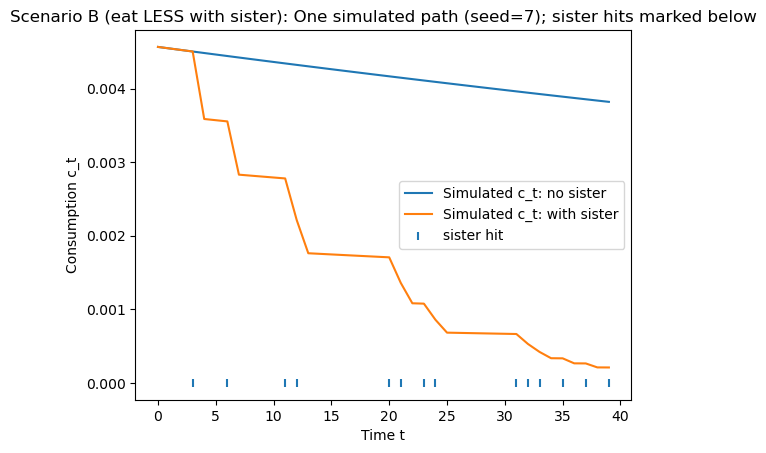
plt.figure()
plt.plot(t, c_path0, label="Simulated c_t: no sister")
plt.plot(t, c_path1, label="Simulated c_t: with sister")
plt.xlabel("Time t")
plt.ylabel("Consumption c_t")
plt.title(f"{name}: One simulated path (seed={seed}); sister hits marked below")
# optional: mark sister-hit times on the x-axis
hit_times = np.where(s)[0]
if len(hit_times) > 0:
y0 = min(c_path0.min(), c_path1.min())
plt.scatter(hit_times, np.full_like(hit_times, y0), marker="|", label="sister hit")
plt.legend()
else:
plt.legend()
plt.show()
if __name__ == "__main__":
# Scenario A (typically: eat MORE with sister)
# Low risk aversion => less precautionary saving; sister makes saving less attractive => consume more now.
run_scenario(
name="Scenario A (eat MORE with sister)",
beta=0.95,
gamma=0.5,
p=0.30,
d=0.20,
x0=1.0,
T=40,
nx=700,
nm=220,
seed=7
)
# Scenario B (typically: eat LESS with sister)
# High risk aversion => precautionary saving can dominate => consume less now.
run_scenario(
name="Scenario B (eat LESS with sister)",
beta=0.95,
gamma=8.0,
p=0.30,
d=0.20,
x0=1.0,
T=40,
nx=700,
nm=220,
seed=7
)
=== Scenario A (eat MORE with sister) ===
params: beta=0.95, gamma=0.5, p=0.3, d=0.2
At x≈1: c_no_sister=0.0959, c_sister=0.1553, diff=+0.0594
Mean diff over grid: +0.029486
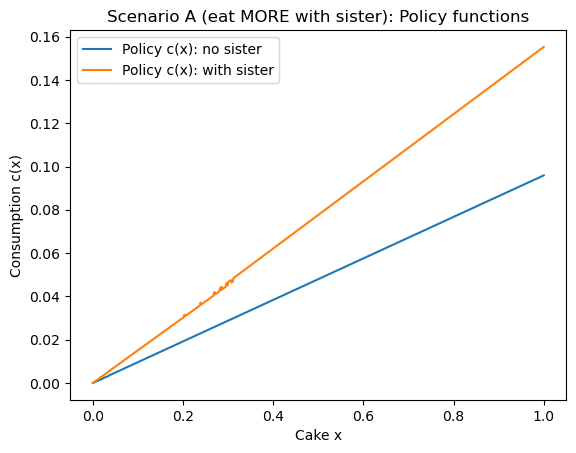
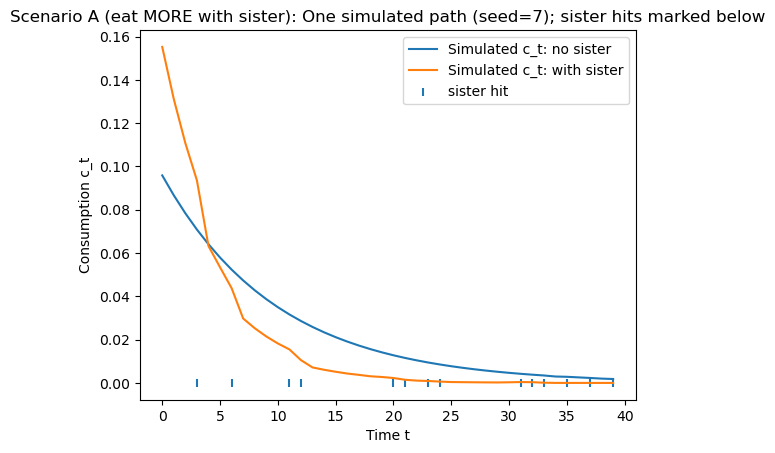
=== Scenario B (eat LESS with sister) ===
params: beta=0.95, gamma=8.0, p=0.3, d=0.2
At x≈1: c_no_sister=0.0046, c_sister=0.0046, diff=+0.0000
Mean diff over grid: +0.000000
Deterministic Bellman equation in a standard consumption choice model¶
State , action . Deterministic law . Discount factor .
The Bellman equation:
Example (deterministic consumption–savings):
State: assets . Control: next-period assets (or consumption ). Budget: .
Bellman:
Using the envelope theorem and FOC you can derive the Euler equation when interior.
Stochastic Bellman equation¶
With Markov income shock and assets :
We typically discretize assets and the shock support, then compute the Bellman operator on the finite grid.
Contraction Mappings: Intuition and Simple Examples¶
A contraction mapping is a function that brings points closer together every time you apply it.
Formally, a function on a space with distance is a contraction if:
Key properties:
Monotonicity: if then .
Contraction: , so with Banach fixed-point gives a unique solution and geometric convergence of iterates.
Why is this important?¶
The Contraction Mapping Theorem (Banach Fixed Point Theorem) says:
If is a contraction on a complete space , then:
There exists a unique fixed point such that .
Starting from any initial , repeated iteration converges to .
This is the foundation of dynamic programming — the Bellman operator is a contraction, and its fixed point is the unique value function .
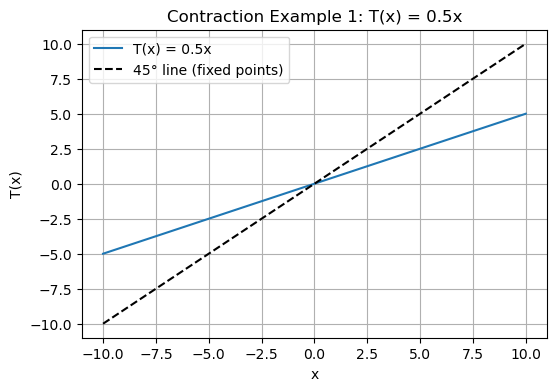
Example 1: A Simple Shrinking Function¶
Let .
Then:
It’s a contraction, and the fixed point satisfies
Define operator on bounded functions:
import numpy as np
import matplotlib.pyplot as plt
# Example 1: T(x) = 0.5x
T = lambda x: 0.5 * x
x_vals = np.linspace(-10, 10, 200)
plt.figure(figsize=(6,4))
plt.plot(x_vals, T(x_vals), label="T(x) = 0.5x")
plt.plot(x_vals, x_vals, 'k--', label="45° line (fixed points)")
plt.title("Contraction Example 1: T(x) = 0.5x")
plt.xlabel("x")
plt.ylabel("T(x)")
plt.legend()
plt.grid(True)
plt.show()
Example 2: Adding a Constant¶
Let (T(x) = 0.5x + 2.
Then:
So it’s still a contraction, but now the fixed point satisfies
# Example 2: T(x) = 0.5x + 2
T = lambda x: 0.5 * x + 2
# Iterate starting from any x0
x0 = 0
x_vals = [x0]
for _ in range(10):
x_vals.append(T(x_vals[-1]))
print("Fixed point should be 4")
print("Iterates:", x_vals)Fixed point should be 4
Iterates: [0, 2.0, 3.0, 3.5, 3.75, 3.875, 3.9375, 3.96875, 3.984375, 3.9921875, 3.99609375]
📘 Conditions for a Contraction Mapping¶
A contraction mapping is a function that brings points closer together every time it is applied.
Formally, let be a metric space.
A mapping is a contraction if there exists a constant such that
for all
Here, is called the contraction modulus — it measures how much the mapping shrinks distances.
🧩 Necessary Conditions (for Banach’s Fixed Point Theorem)¶
For the Contraction Mapping Theorem (also called the Banach Fixed Point Theorem) to apply, the following conditions must hold:
1️⃣ The space must be complete¶
The space must be complete — meaning every Cauchy sequence in converges to a point that is also in .
Example: with is complete ✅
Example: (rational numbers) is not complete ❌ (some Cauchy sequences converge to irrational limits)
2️⃣ The mapping must map the space into itself¶
For all , we must have .
That is, takes elements of and returns elements still in .
Example: If and , then , so it maps the interval into itself ✅.
3️⃣ The mapping must shrink distances¶
There must exist a constant with such that
for all
This ensures that the function pulls points closer together with each application.
Example: satisfies
,
so — it is a contraction ✅.
4️⃣ (Optional but common) The mapping is continuous¶
While continuity is not required for Banach’s theorem, most contraction mappings encountered in practice (especially in economics or numerical analysis) are continuous.
✅ Summary Table¶
| Condition | Meaning | Example |
|---|---|---|
| Completeness | is complete | with $ |
| Self-mapping | for all | |
| Distance shrinking | with | |
| Continuity (optional) | Smooth, no jumps | Continuous |
💡 Economic Example: Bellman Operator¶
In dynamic programming, the Bellman operator
is a contraction with modulus when and is bounded.
Then,
which means repeated application converges to the unique value function satisfying .
🧠 Key Takeaway¶
A function is a contraction mapping if it:
Acts on a complete metric space,
Maps the space into itself, and
Shrinks distances by a constant factor .
Then, the Banach Fixed Point Theorem guarantees:
A unique fixed point ,
Convergence of iteration from any start ,
Geometric rate of convergence: .
Numerical methods — overview¶
Common approaches:
Value Function Iteration (VFI) — robust but can be slow when discount factor is close to 1 or state grid is large.
Policy Iteration / Howard’s improvement — often faster; requires solving linear systems (finite state).
Endogenous Grid Method (EGM) — very fast for single-state consumption–savings problems where Euler equation is invertible.
Collocation / projection methods — approximate value function with basis functions; powerful for smooth problems in continuous state spaces.
Numerical example: VFI (Python)¶
The cell below contains a runnable implementation of Value Function Iteration for a small CRRA consumption–savings model with two income states. Run it to compute the value functions and the policy function (next-period assets) and plot the results.
# VFI implementation for a simple consumption-savings problem with discrete income (runnable)
# This version has extra inline comments explaining shapes, broadcasting, and algorithmic steps.
import numpy as np
import matplotlib.pyplot as plt
# -------------------------
# Model parameters
# -------------------------
# Discount factor: how much agents value the future vs present
beta = 0.96
# Interest rate on assets (gross return = 1 + r)
r = 0.04
# CRRA risk aversion parameter (gamma = 1 is log utility; here we use 2 as a common example)
gamma = 2.0
# Asset grid: we discretize assets between a_min and a_max with Na points
a_min, a_max, Na = 0.0, 20.0, 200
a_grid = np.linspace(a_min, a_max, Na) # shape (Na,)
# -------------------------
# Income process (discrete)
# -------------------------
# Two income states for simplicity: low and high
y_vals = np.array([0.5, 1.5]) # shape (Ny,) where Ny = 2
# Transition matrix P: P[iy, jy] = Prob(y' = jy | current y = iy)
# Rows should sum to 1. Here we use a simple persistence structure.
P = np.array([[0.9, 0.1],
[0.1, 0.9]]) # shape (Ny, Ny)
# -------------------------
# Utility function
# -------------------------
def utility(c):
"""CRRA utility with safeguard to avoid taking powers/log of nonpositive numbers.
This function accepts array input via numpy broadcasting and returns an array of same shape.
"""
c_safe = np.maximum(c, 1e-12) # prevent nonpositive consumption
if gamma == 1.0:
return np.log(c_safe)
else:
return (c_safe ** (1.0 - gamma)) / (1.0 - gamma)
# -------------------------
# Value function initialization
# -------------------------
# V[a_index, y_index] stores the value of being at assets a_grid[a_index] and income y_vals[y_index]
V = np.zeros((Na, len(y_vals))) # initial guess: zeros
# Convergence settings
tol = 1e-6
max_iter = 2000
# -------------------------
# Value Function Iteration (VFI)
# -------------------------
# The main loop performs Bellman updates until V converges.
# At each iteration and for each current income state 'iy' we:
# 1. For each current asset a (index ia), consider all candidate next-period assets a' (indexed by ia_prime).
# 2. Compute feasible consumption c = (1+r)*a + y - a' for each pair (a, a').
# This produces a matrix of shape (Na, Na) where rows correspond to current a and columns to a'.
# 3. Compute one-period utility U(c) for the entire (Na, Na) matrix.
# 4. Compute the expected continuation value for each candidate a' as:
# E[V(a', y')] = sum_{y'} P[iy, y'] * V[a_prime_index, y']
# This yields a vector of length Na (indexed by a').
# 5. Add the discounted continuation value to the one-period utility (broadcasted over rows).
# 6. Maximize over a' (columns) to update V_new[a, iy].
#
# Vectorization notes:
# - We build the consumption matrix c with broadcasting: a_grid[:, None] (shape (Na,1)) and a_grid[None, :] (shape (1,Na)).
# - The continuation value cont is computed as an expected value across next-period income states using matrix multiply.
# - cont has shape (Na,) and is added to every row of U (hence cont[None, :]).
for it in range(max_iter):
V_new = np.empty_like(V) # placeholder for updated value function
# Loop over current income states (small dimension Ny = 2 here — looping is fine)
for iy, y in enumerate(y_vals):
# Build candidate consumption matrix:
# For current assets along rows (shape (Na,1)) and a' along columns (shape (1,Na))
# c[ia, ia_prime] = (1+r)*a_grid[ia] + y - a_grid[ia_prime]
c = (1.0 + r) * a_grid[:, None] + y - a_grid[None, :]
c = np.maximum(c, 1e-12) # enforce nonnegativity for numerical stability
# One-period utility for every (a, a') pair: shape (Na, Na)
U = utility(c)
# Expected continuation value for each candidate a' (vector of length Na):
# P[iy, :] is the row of transition probabilities from current income state iy
# V.T has shape (Ny, Na) after transpose, so (P[iy, :] @ V.T) yields a vector of length Na
# Multiply by beta to discount future utility.
cont = beta * (P[iy, :] @ V.T).T # shape (Na,)
# Right-hand side: one-period utility + discounted expected continuation value
# We add cont[None, :] (shape (1, Na)) to U (shape (Na, Na)); broadcasting applies across rows.
RHS = U + cont[None, :]
# Maximize over columns (a' choices) for each row (current a)
# axis=1 corresponds to maximizing across candidate a' for each current a
V_new[:, iy] = np.max(RHS, axis=1)
# Compute sup-norm difference for convergence check
diff = np.max(np.abs(V_new - V))
V[:] = V_new # update value function
if diff < tol:
print(f'Converged after {it+1} iterations, diff={diff:.2e}')
break
else:
print('VFI did not converge within max_iter')
# -------------------------
# Recovering the policy function
# -------------------------
# After convergence, recover the argmax (policy) that attains the maximum for each (a, y).
# policy_idx[a_index, y_index] = index of a' chosen (an integer index into a_grid)
policy_idx = np.empty_like(V, dtype=int)
for iy, y in enumerate(y_vals):
# Recompute the same RHS components to obtain argmax (this repeats some computation;
# in production code you might store argmax during the VFI loop to avoid recomputing)
c = (1.0 + r) * a_grid[:, None] + y - a_grid[None, :]
c = np.maximum(c, 1e-12)
U = utility(c)
cont = beta * (P[iy, :] @ V.T).T
RHS = U + cont[None, :]
policy_idx[:, iy] = np.argmax(RHS, axis=1) # index of optimal a' for each current a
# Convert index to actual asset choices a' (policy in levels)
policy_a_prime = a_grid[policy_idx] # shape (Na, Ny)
# -------------------------
# Plots: value functions and policy functions
# -------------------------
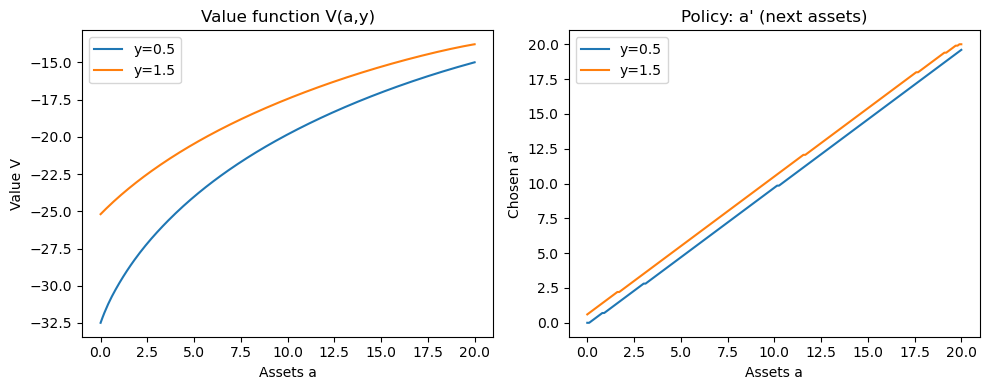
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# Value functions for the two income states
axes[0].plot(a_grid, V[:, 0], label=f'y={y_vals[0]}')
axes[0].plot(a_grid, V[:, 1], label=f'y={y_vals[1]}')
axes[0].set_title('Value function V(a,y)')
axes[0].set_xlabel('Assets a')
axes[0].set_ylabel('Value V')
axes[0].legend()
# Policy: a' choice as function of current assets for each income state
axes[1].plot(a_grid, policy_a_prime[:, 0], label=f'y={y_vals[0]}')
axes[1].plot(a_grid, policy_a_prime[:, 1], label=f'y={y_vals[1]}')
axes[1].set_title("Policy: a' (next assets)")
axes[1].set_xlabel('Assets a')
axes[1].set_ylabel("Chosen a'")
axes[1].legend()
plt.tight_layout()
plt.show()
Converged after 337 iterations, diff=9.91e-07
Endogenous Grid Method (EGM) — intuition & sketch¶
EGM is useful when the problem’s Euler equation can be inverted easily (e.g., CRRA utility and a single continuous state like assets).
Key idea:
Work on grid for next-period assets .
Compute expected marginal utility of consumption tomorrow on that grid.
Invert the Euler equation to get current consumption at the implied current asset .
This produces (a, c(a)) pairs that are interpolated back onto the original asset grid.
EGM avoids root finding at each and is often substantially faster than naive VFI for single-state problems.
Exercises (in-class / take-home)¶
Deterministic growth model. Implement VFI for the deterministic growth model with log utility and Cobb–Douglas production . Compute policy and value functions.
Two-state income. Modify the VFI above to increase Na and explore how solution time scales. Try different gamma values.
EGM practice. Implement the EGM for the consumption–savings model (single-state stochastic income if you like). Compare runtime vs VFI for a moderate grid.
Policy iteration. For a finite-state discretized model, implement policy iteration and compare number of iterations to VFI for high beta (e.g., beta=0.99).
Suggested readings¶
Stokey, Lucas & Prescott (1989), Recursive Methods in Economic Dynamics.
Judd (1998), Numerical Methods in Economics.
Ljungqvist & Sargent, Recursive Macroeconomic Theory.
Carroll (2006), “The method of endogenous gridpoints for solving dynamic stochastic optimization problems”.
Endogenous Grid Method (EGM) — commented implementation and runtime comparison¶
Below we provide:
A clear, commented implementation of the Endogenous Grid Method (EGM) for a single-state consumption–savings model (CRRA utility, deterministic labor income).
A comparable VFI implementation for the same deterministic model (so the two methods solve the same problem).
A runtime comparison across several asset-grid sizes to illustrate the computational advantages of EGM in this canonical setting.
Notes:
For clarity we implement the deterministic-income version of the model (no stochastic shocks).
The EGM algorithm implemented here follows the common textbook recipe:
Start with an initial guess for the consumption policy on the asset grid.
Given the previous period consumption function, compute marginal utility next period at each a’.
Invert Euler to get current consumption at the implied current asset (endogenous grid).
Interpolate the resulting (a_implied, c_current) pairs back to the original a_grid.
Repeat until the consumption policy converges.
# EGM vs VFI: implementations and timing comparison
import numpy as np
import time
import matplotlib.pyplot as plt
from scipy import interpolate
# -------------------------
# Model primitives (deterministic income)
# -------------------------
beta = 0.96 # discount factor
r = 0.04 # interest rate
gamma = 2.0 # CRRA risk aversion (gamma=1 is log utility)
y = 1.0 # deterministic income each period
a_min = 0.0 # borrowing constraint (natural boundary)
# We'll vary a_max and Na (grid size) below for timing comparison.
# Utility and marginal utility functions
def u(c):
c_safe = np.maximum(c, 1e-12)
if gamma == 1.0:
return np.log(c_safe)
else:
return (c_safe ** (1.0 - gamma)) / (1.0 - gamma)
def mu(c):
# marginal utility u'(c) = c^{-gamma} for CRRA
c_safe = np.maximum(c, 1e-12)
return c_safe ** (-gamma)
def mu_inv(mu_val):
# inverse marginal utility: given marginal utility, return c
# For CRRA: mu = c^{-gamma} => c = mu^{-1/gamma}
return mu_val ** (-1.0 / gamma)
# -------------------------
# VFI implementation for deterministic model (function)
# -------------------------
def solve_vfi_det(a_grid, beta=beta, r=r, y=y, tol=1e-6, max_iter=2000):
"""Solve deterministic consumption-savings via naive VFI on given asset grid.
Returns: consumption policy c_policy (shape Na,), value function V (Na,), and timing info.
"""
Na = len(a_grid)
V = np.zeros(Na) # initial guess for value function
c_policy = np.zeros(Na) # to store policy in levels
# Precompute resource (cash-on-hand) for state a and candidate a'
# We'll vectorize across a (rows) and a' (cols)
A = a_grid[:, None] # shape (Na,1)
Aprime = a_grid[None, :] # shape (1,Na)
start = time.perf_counter()
for it in range(max_iter):
V_new = np.empty_like(V)
# compute RHS for all (a, a') pairs
cons = (1.0 + r) * A + y - Aprime # shape (Na, Na)
cons = np.maximum(cons, 1e-12)
U = u(cons) # shape (Na, Na)
# continuation value is V evaluated at a' (vector length Na), broadcast across rows
cont = beta * V[None, :] # shape (1, Na)
RHS = U + cont # shape (Na, Na)
V_new = np.max(RHS, axis=1) # max over columns (a') for each row (current a)
# Check convergence
diff = np.max(np.abs(V_new - V))
V[:] = V_new
if diff < tol:
break
end = time.perf_counter()
# Recover policy (argmax)
cons = (1.0 + r) * A + y - Aprime
cons = np.maximum(cons, 1e-12)
U = u(cons)
cont = beta * V[None, :]
RHS = U + cont
idx = np.argmax(RHS, axis=1)
c_policy = cons[np.arange(Na), idx]
return c_policy, V, end - start, it+1
# -------------------------
# EGM implementation for deterministic model (function)
# -------------------------
def solve_egm_det(a_grid, beta=beta, r=r, y=y, tol=1e-6, max_iter=2000):
"""Solve deterministic consumption-savings via EGM with safe interpolation."""
Na = len(a_grid)
# initial guess: consume half of cash-on-hand
c_policy = 0.5 * ((1.0 + r) * a_grid + y)
c_policy = np.maximum(c_policy, 1e-12)
start = time.perf_counter()
for it in range(max_iter):
# 1) next-period consumption on a' grid
c_next = c_policy.copy()
# 2) next-period marginal utility
muc_next = mu(c_next)
# 3) invert Euler: u'(c) = beta(1+r)u'(c')
factor = beta * (1.0 + r) * muc_next
# guard against numerical under/overflow
factor = np.maximum(factor, 1e-300)
c_current_at_a_prime = mu_inv(factor)
# 4) implied current asset that leads to (c_current, a')
a_implied = (c_current_at_a_prime + a_grid - y) / (1.0 + r)
# 5) borrowing constraint handling: if a_implied < a_min, the correct solution is a=a_min
mask_below = a_implied < a_min
if np.any(mask_below):
a_implied[mask_below] = a_min
# at the constraint the optimal a' is a_min; consumption there is c = (1+r)a_min + y - a'
# since we are sitting at a=a_min, set a' = a_min for the constraint point
# i.e., c = y + r*a_min - a_min = y + (r-1)*a_min; with a_min=0 this is y
c_current_at_a_prime[mask_below] = (1.0 + r) * a_min + y - a_min
# 6) sort by a_implied and collapse duplicate x's (take max c for each unique a)
sort_idx = np.argsort(a_implied)
x = a_implied[sort_idx]
y_c = c_current_at_a_prime[sort_idx]
# collapse duplicates robustly
unique_x = []
unique_c = []
i = 0
n = x.size
while i < n:
j = i + 1
while j < n and x[j] == x[i]:
j += 1
unique_x.append(x[i])
# at duplicated a (notably a_min), keep the largest feasible consumption
unique_c.append(np.max(y_c[i:j]))
i = j
x = np.asarray(unique_x)
y_c = np.asarray(unique_c)
# ensure we have the constraint anchor explicitly (use correct c at a_min)
if x[0] > a_min:
x = np.insert(x, 0, a_min)
y_c = np.insert(y_c, 0, (1.0 + r) * a_min + y - a_min)
# if any tiny non-monotonicity remains, enforce strictly increasing x by jittering eps
# (rarely needed, but keeps interp1d happy)
eps = 0.0
for k in range(1, x.size):
if x[k] <= x[k-1]:
eps = max(eps, 1e-12 * (1.0 + abs(x[k-1])))
x[k] = x[k-1] + eps
# 7) interpolate back to the original grid
interp = interpolate.interp1d(x, y_c, kind='linear', bounds_error=False, fill_value='extrapolate')
c_new = interp(a_grid)
c_new = np.maximum(c_new, 1e-12)
# 8) convergence
diff = np.max(np.abs(c_new - c_policy))
c_policy[:] = c_new
if diff < tol:
break
end = time.perf_counter()
return c_policy, end - start, it + 1
# -------------------------
# Timing comparison across grid sizes
# -------------------------
grid_sizes = [100, 200, 400, 800] # adjust depending on runtime tolerance in this environment
vfi_times = []
egm_times = []
vfi_iters = []
egm_iters = []
for Na in grid_sizes:
a_max = 50.0
a_grid = np.linspace(a_min, a_max, Na)
# Time VFI (deterministic)
c_vfi, V_vfi, t_vfi, it_vfi = solve_vfi_det(a_grid)
vfi_times.append(t_vfi)
vfi_iters.append(it_vfi)
# Time EGM
c_egm, t_egm, it_egm = solve_egm_det(a_grid)
egm_times.append(t_egm)
egm_iters.append(it_egm)
print(f"Na={Na}: VFI time={t_vfi:.4f}s (iters={it_vfi}), EGM time={t_egm:.4f}s (iters={it_egm})")
# -------------------------
# Plot timing results
# -------------------------
plt.figure(figsize=(6,4))
plt.plot(grid_sizes, vfi_times, marker='o', label='VFI (deterministic)')
plt.plot(grid_sizes, egm_times, marker='o', label='EGM')
plt.xlabel('Number of asset grid points (Na)')
plt.ylabel('Compute time (seconds)')
plt.title('Runtime comparison: VFI vs EGM (deterministic model)')
plt.legend()
plt.grid(True)
plt.show()
# -------------------------
# Show policy functions for the finest grid
# -------------------------
Na = grid_sizes[-1]
a_grid = np.linspace(a_min, 50.0, Na)
c_vfi, V_vfi, t_vfi, it_vfi = solve_vfi_det(a_grid)
c_egm, t_egm, it_egm = solve_egm_det(a_grid)
plt.figure(figsize=(8,4))
plt.plot(a_grid, c_vfi, label='VFI consumption policy')
plt.plot(a_grid, c_egm, label='EGM consumption policy', linestyle='--')
plt.xlabel('Assets a')
plt.ylabel('Consumption c(a)')
plt.title(f'Policy functions (Na={Na}) — VFI vs EGM')
plt.legend()
plt.grid(True)
plt.show()
Na=100: VFI time=0.0138s (iters=340), EGM time=0.0614s (iters=278)
Na=200: VFI time=0.0326s (iters=340), EGM time=0.1115s (iters=278)
Na=400: VFI time=0.1362s (iters=340), EGM time=0.2060s (iters=278)
Na=800: VFI time=0.9397s (iters=340), EGM time=0.4081s (iters=278)
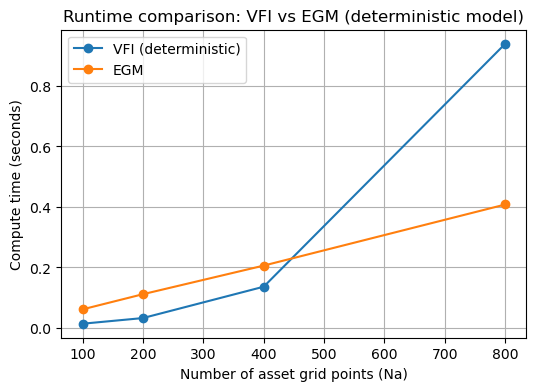
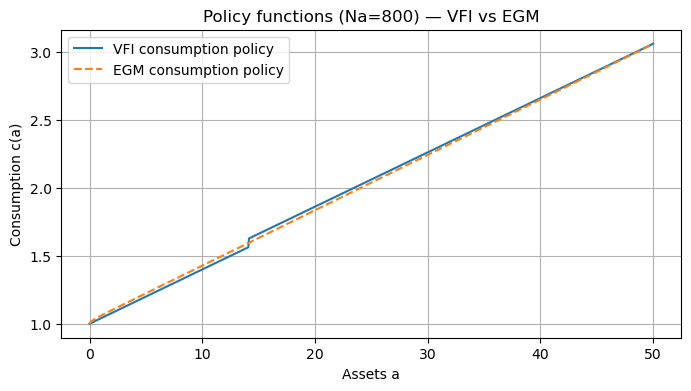
Notes on the comparison¶
The EGM method here solves the same deterministic problem more efficiently because it avoids maximizing over a’ at each grid point; instead it constructs a mapping from a’ to implied a and inverts it via interpolation.
For stochastic problems with Markov income, EGM can be extended but requires computing expected marginal utilities (integration over shocks), which slightly complicates the implementation — the performance advantages generally remain for single-state control problems.
The runtime numbers printed above are illustrative and will depend on the machine and environment; they show how EGM scales more gently with grid size compared to naive VFI.
EGM extended to discrete Markov income (stochastic EGM)¶
This section implements the Endogenous Grid Method (EGM) for a consumption–savings problem with a discrete Markov income process. The key difference from the deterministic EGM is that the expected marginal utility next period must average over the possible income states next period using the transition matrix.
We implement solve_egm_stochastic which iterates on the consumption policy
c(a, y) defined on a grid of assets and on the discrete income states.
The algorithm (high level) for each current income state y_i:
For each candidate next asset a’ (grid point), collect c_next(a’, y’) across all possible y’ (from previous iterate).
Compute expected marginal utility: muc_next(a’) = sum_{y’} P[y_i, y’] * u’( c_next(a’, y’) ).
Invert Euler to get current consumption c(a_implied, y_i) at each a’ via c = (beta*(1+r)*muc_next)^{-1/gamma}.
Compute implied current asset a_implied = (c + a’ - y_i) / (1+r).
Handle points where a_implied < borrowing constraint and interpolate to map back to the original grid.
The function returns the converged consumption policy c_policy (shape Na x Ny), timing, and iterations.
from IPython.display import HTML, display
display(HTML("""
<style>
/* Expand notebook width */
.container {
width: 100% !important;
}
/* Disable output scrolling */
.output_scroll {
height: auto !important;
max-height: none !important;
overflow-y: visible !important;
}
/* Also expand output area width */
.output_wrapper, .output {
overflow-x: visible !important;
}
</style>
"""))
# EGM for stochastic income (discrete Markov) + demo run
import numpy as np
import time
import matplotlib.pyplot as plt
from scipy import interpolate
# Model primitives (shared)
beta = 0.96
r = 0.04
gamma = 2.0
a_min = 0.0
def mu(c):
c_safe = np.maximum(c, 1e-12)
return c_safe ** (-gamma)
def mu_inv(mu_val):
return mu_val ** (-1.0 / gamma)
# -------------------------
# Stochastic EGM solver
# -------------------------
def solve_egm_stochastic(a_grid, y_vals, P, beta=beta, r=r, tol=1e-6, max_iter=2000):
"""Endogenous Grid Method for a model with discrete Markov income.
Inputs:
- a_grid: 1D array of asset grid points (Na,)
- y_vals: 1D array of income states (Ny,)
- P: transition matrix shape (Ny, Ny) with rows summing to 1
Returns:
- c_policy: consumption policy array shape (Na, Ny) mapping (a, y) -> c
- elapsed_time: seconds
- n_iter: iterations taken
Notes:
- We iterate on the consumption policy c(a, y).
- For each current income state i and for each a' in the grid we compute expected
marginal utility using P[i, :], invert Euler, get implied a, then interpolate.
"""
Na = len(a_grid)
Ny = len(y_vals)
# Initial guess: consume a fraction of cash-on-hand for each income state
# cash on hand = (1+r)*a + y, choose to consume half of it initially
coh = (1.0 + r) * a_grid[:, None] + y_vals[None, :] # shape (Na, Ny)
c_policy = 0.5 * coh # initial c(a,y), shape (Na, Ny)
c_policy = np.maximum(c_policy, 1e-12)
start = time.perf_counter()
for it in range(max_iter):
c_new = np.empty_like(c_policy)
# For each current income state y_i compute implied a and c from a' grid
for iy, y in enumerate(y_vals):
# For each candidate a' (index j), we need c_next at (a'=a_grid[j], every y')
# Extract c_next(a', y') as a vector of length Ny for each a' -- that's c_policy[j, :].
# We'll loop over a' index vectorized with array ops.
# c_next_matrix has shape (Na, Ny) where row j corresponds to a'=a_grid[j] across y'
c_next_matrix = c_policy.copy() # shape (Na, Ny): rows are a' indices
# Compute marginal utility at next period for each (a', y') -> shape (Na, Ny)
muc_next = mu(c_next_matrix) # shape (Na, Ny)
# Compute expected marginal utility conditional on current income state iy:
# For each a' (row), take inner product with P[iy, :] over columns (y' dimension)
# This yields a vector of length Na: muc_exp[j] = sum_{y'} P[iy, y'] * muc_next[j, y']
muc_exp = muc_next @ P[iy, :].T # shape (Na,) (matrix-vector multiplication)
# Invert Euler condition for each a' to get current consumption associated with that a'
factor = beta * (1.0 + r) * muc_exp
c_current_at_aprime = mu_inv(factor) # shape (Na,)
# Get implied current asset for each a' using budget identity:
# a = (c + a' - y) / (1+r)
a_implied = (c_current_at_aprime + a_grid - y) / (1.0 + r) # shape (Na,)
# Handle borrowing constraint: where a_implied < a_min, set a_implied = a_min and recompute c
mask = a_implied < a_min
if np.any(mask):
a_implied[mask] = a_min
# recompute c for these a' from budget: c = (1+r)*a_min + y - a'
c_current_at_aprime[mask] = (1.0 + r) * a_min + y - a_grid[mask]
# Now we have pairs (a_implied, c_current_at_aprime) of length Na.
# Sort by a_implied (necessary for monotone interpolation)
sort_idx = np.argsort(a_implied)
a_sorted = a_implied[sort_idx]
c_sorted = c_current_at_aprime[sort_idx]
# Remove duplicate a's to avoid zero denominators in slope calculation
a_unique, unique_idx = np.unique(a_sorted, return_index=True)
c_unique = c_sorted[unique_idx]
# Interpolate onto original a_grid to get c(a_grid, y_i)
interp = interpolate.interp1d(a_unique, c_unique, kind='linear',
bounds_error=False, fill_value='extrapolate')
c_on_grid = interp(a_grid)
c_on_grid = np.maximum(c_on_grid, 1e-12)
c_new[:, iy] = c_on_grid
# Convergence check across all (a,y)
diff = np.max(np.abs(c_new - c_policy))
c_policy[:] = c_new
if diff < tol:
break
elapsed = time.perf_counter() - start
return c_policy, elapsed, it+1
# -------------------------
# Demo run: small Markov income process
# -------------------------
y_vals = np.array([0.5, 1.5]) # low and high income
P = np.array([[0.9, 0.1],
[0.1, 0.9]]) # transition matrix (rows sum to 1)
Na = 400
a_max = 50.0
a_grid = np.linspace(a_min, a_max, Na)
c_stoch_egm, t_stoch_egm, it_stoch_egm = solve_egm_stochastic(a_grid, y_vals, P)
print(f'Stochastic EGM converged in {it_stoch_egm} iters, time {t_stoch_egm:.4f}s')
# Plot policy functions for each income state
plt.figure(figsize=(8,4))
plt.plot(a_grid, c_stoch_egm[:,0], label=f'EGM c(a, y_low={y_vals[0]})')
plt.plot(a_grid, c_stoch_egm[:,1], label=f'EGM c(a, y_high={y_vals[1]})', linestyle='--')
plt.xlabel('Assets a')
plt.ylabel('Consumption c(a,y)')
plt.title('Stochastic EGM: Consumption policy by income state')
plt.legend()
plt.grid(True)
plt.show()Stochastic EGM converged in 2000 iters, time 0.3078s
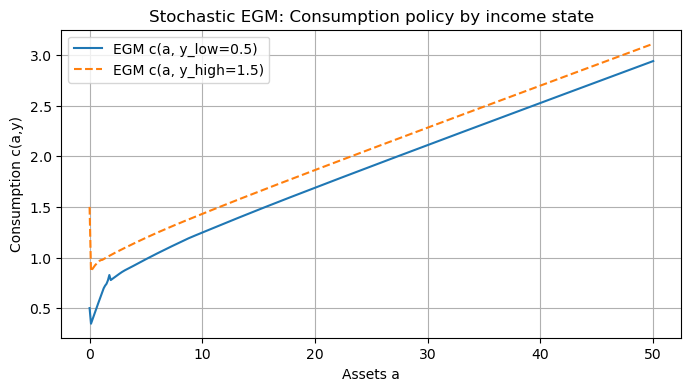
Notes¶
This stochastic EGM iterates on the consumption policy across both assets and income states.
Performance depends on Ny (number of income states) and Na (asset grid size). Expect runtime to scale roughly linearly in Ny for fixed Na.
For smoother interpolation or better handling of kinks near borrowing constraints, one can use piecewise-linear splines or monotone cubic interpolation, but linear interpolation is robust and simple.
## 8. (Optional) Minimal Python illustration: value iteration for a small MDP
# simple value iteration for a small finite MDP
import numpy as np
# example: 2 states, 2 actions
P = {
0: {0: [(1.0,0)], 1: [(1.0,1)]}, # action 0 keeps state 0, action 1 moves to state 1
1: {0: [(1.0,1)], 1: [(1.0,1)]} # absorbing state 1
}
R = {
(0,0): 1.0, (0,1): 2.0,
(1,0): 0.0, (1,1): 0.0
}
beta = 0.9
V = np.zeros(2)
for it in range(100):
V_new = V.copy()
for s in [0,1]:
vals = []
for a in [0,1]:
expV = sum(p * V[s2] for (p,s2) in P[s][a])
vals.append(R[(s,a)] + beta*expV)
V_new[s] = max(vals)
if np.max(np.abs(V_new - V)) < 1e-8:
break
V = V_new
print("Value function:", V)Value function: [9.9997639 0. ]